

Google Cloud Custom Metrics

I'm an Engineer at The @ Company, building the @platform, a technology that is putting people in control of their data and removing the frictions and surveillance associated with today’s Internet. I was previously a Fellow at DXC Technology where I held various CTO roles. Before that I held CTO and Director of R&D roles at Cohesive Networks, UBS, Capital SCF and Credit Suisse, where I worked on app servers, compute grids, security, mobile, cloud, networking and containers.
For a long while we ran The atPlatform on Ubuntu Linux, but we found that doing stuff with nodes on a large Docker Swarm spiked CPU usage for cloud-init. Every start or stop of a container was a change to networking, and every change to networking caused cloud-init to burn CPU (usually at times when the CPU should be busy on other things).
So we started the shift to Flatcar Linux, a container focussed distribution that picked up what CoreOS had been doing before RedHat decided to kill it off.
But there was a problem. We were using the Google Ops Agent to get metrics from inside our Ubuntu VMs, and Flatcar isn't one of the supported distros. I raised an issue with the Flatcar team, but it quickly became clear that Ops Agent wasn't a good fit for their approach.
Meanwhile we noticed that our monitoring bill was HUGE. It turns out that the default for Ops Agent is to monitor every process (in detail), which can get expensive when you're running hundred to thousands of containers per node :0
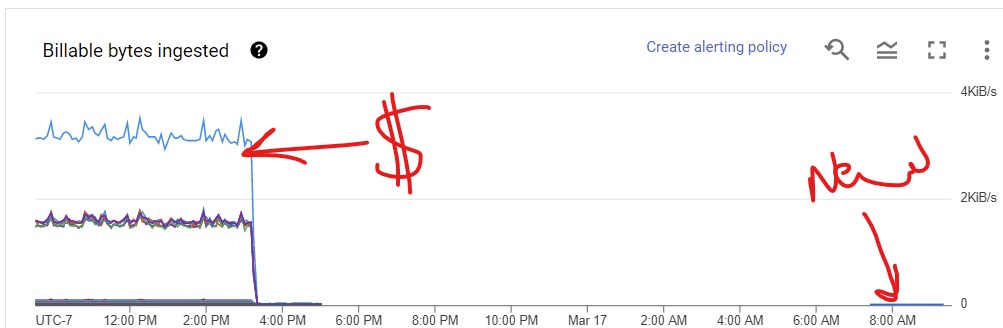
We shut down Ops Agent, and briefly replaced it with a 'ghetto' monitoring script. But this was the push we needed to get a custom metrics solution in place.
Of course there's an API for Stackdriver, and like most things Google Cloud there's good support for Python and Golang SDKs. A quick search brought me to Arpana Mehta's Getting started with Google Cloud Monitoring APIs, which had the boilerplate code I needed to customise. After adding in CPU Load Average, I had our most crucial metric (and I returned to my script a few days later to add in root volume utilisation).
With a working script in the staging environment I then packaged it up (along with the google-cloud-monitoring package) into a Docker container that could be deployed across our Swarm nodes. After less than a day of 'ghetto' monitoring we were back to seeing everything we needed in our dashboard, with much lower ingestion and storage charges, as we're only sending the metrics we need rather than everything about everything.
The script, Dockerfile etc. are now open source - at_swarm_load.
We've also found that the same approach can be used to monitor our CI/CD VMs on AWS. It's a little more fiddly, due to the need for service account files, but means we can use a single dashboard to keep an eye on things.

